Moving initializr to new JS port#4795
Conversation
37159a9 to
e273251
Compare
✅ Continuous Quality ReportTest & Coverage
Static Analysis
Generated automatically by the PR CI workflow. |
Cloudflare Preview
|
JavaScript port screenshot updatesCompared 18 screenshots: 0 matched, 18 missing references.
|












|
Compared 89 screenshots: 89 matched. Benchmark Results
Build and Run Timing
Detailed Performance Metrics
|
✅ ByteCodeTranslator Quality ReportTest & Coverage
Benchmark Results
Static Analysis
Generated automatically by the PR CI workflow. |
|
Compared 89 screenshots: 89 matched. Native Android coverage
✅ Native Android screenshot tests passed. Native Android coverage
Benchmark ResultsDetailed Performance Metrics
|
766a374 to
6c6c483
Compare
The raw ByteCodeTranslator JS output for Initializr was a single 90 MiB
translated_app.js that Cloudflare Pages refused to upload (25 MiB per-file
cap). Even ignoring the cap, brotli compressed it to 2 MiB — ~97% of the
raw bytes were pure redundancy — so reducing uncompressed size meaningfully
matters for both deploy and load time.
This lands four layered optimisations:
1. cn1_iv0..cn1_iv4 / cn1_ivN runtime helpers (parparvm_runtime.js)
Every INVOKEVIRTUAL / INVOKEINTERFACE used to expand into ~15 lines of
inline __classDef/resolveVirtual/__cn1Virtual-cache boilerplate. On
Initializr that pattern alone was ~24 MiB across 35k call sites. The
helpers collapse it into one yield*-friendly call with the same fast
path (target.__classDef.methods lookup) and fallback (jvm.resolveVirtual
owns the class-wide cache already). Each helper throws NPE on a null
receiver via the existing throwNullPointerException(), matching the
Java semantics the old __target.__classDef dereference gave for free.
2. Switch-case no-op elision (JavascriptMethodGenerator.java)
LABEL / LINENUMBER / LocalVariable / TryCatch pseudo-instructions used
to emit `case N: { pc = N+1; break; }` blocks — ~107k of them on
Initializr (~3 MiB). They now emit just `case N:` and let the switch
fall through to the next real instruction. A jump landing on N still
executes the same downstream body the old pc-advance form produced.
3. translated_app.js chunking (JavascriptBundleWriter.java)
Class bodies are now streamed into bounded chunks (20 MiB cap each).
Lead chunks land as translated_app_N.js; the trailing chunk retains
the jvm.setMain call. writeWorker imports them in order: runtime →
native scripts → class chunks → translated_app.js (setMain last).
4. Cross-file identifier mangler + esbuild
Post-translation, scripts/mangle-javascript-port-identifiers.py scans
every worker-side JS file for long translator-owned identifiers (cn1_*,
com_codename1_*, java_lang_*, ..., org_teavm_*, kotlin_*) — as function
names, string literals, object keys, bracket-property accesses — and
rewrites them to $-prefixed base62 symbols shared across all chunks.
Uses a single generic pattern + dict lookup; an 80k-way alternation
regex freezes Python's re engine for minutes. Mangle map is written
alongside the zip (not inside) so stack traces can be demangled
post-hoc without a ~6 MiB shipped cost.
Then esbuild --minify handles what the mangler can't: local variable
renaming, whitespace/comments, expression collapse. Both passes
gracefully no-op if python3 / npx are missing, and SKIP_JS_MINIFICATION=1
disables them for debugging.
Initializr measured end-to-end (per-file Cloudflare limit is 25 MiB):
Before: 90.0 MiB single file
After: 20.85 MiB across 4 chunks, biggest 6.27 MiB
brotli over the wire: 1.64 MiB
HelloCodenameOne benefits automatically — same build script pattern.
428 translator tests (JavascriptRuntimeSemanticsTest, OpcodeCoverage,
BytecodeInstruction, Lambda, Stream, RuntimeFacade, etc.) pass on the
new runtime and emission paths.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
port.js is imported by worker.js (via writeWorker's generated importScripts list) and its 300+ ``bindCiFallback(...) / bindNative(...)`` calls register overrides keyed on the *translator's* cn1_* method IDs. When the mangler only rewrote translated_app*.js + parparvm_runtime.js, port.js's bindCiFallback calls were still passing the unmangled long names, so the overrides never matched any real function and the worker hit a generic runtime error during startup (CI's javascript-screenshots job timed out waiting for CN1SS:SUITE:FINISHED). Move port.js into the mangler's worker-side file set. We leave browser_bridge.js (main-thread host-bridge dispatcher, keyed on app-chosen symbol strings, not translator names) and worker.js / sw.js (tiny shells) alone, and skip any ``*_native_handlers.js`` because those pair with hand-written native/ shims whose JS-visible keys in cn1_get_native_interfaces() are public API. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
The mangler breaks the JavaScriptPort runtime (port.js) in two specific
places that can't be fixed by a purely textual rewrite:
* Line 594: ``key.indexOf("cn1_") !== 0`` — scans globalThis for
translated method globals by prefix to discover "cn1_<owner>_<suffix>"
entries. After mangling, those globals are named "$a", "$b" etc.
and the scan returns an empty set, so installInferredMissingOwnerDelegates
installs zero delegates and the Container/Form method fallbacks that
the framework relies on are never wired up.
* Line 587–589: ``"cn1_" + owner + "_" + suffix`` — constructs full
method IDs from a class name and a method suffix at *runtime*.
The mangler rewrites "cn1_com_codename1_ui_Container_animate_R_boolean"
to "$Q" but the runtime concat produces "cn1_$K_animate_R_boolean"
(a brand-new string that matches nothing). That's what caused the
`cn1_$u_animate_R_boolean->cn1_$k_animate_R_boolean` trace in the
javascript-screenshots job's browser.log.
Even without the mangler, the chain of (1) cn1_iv* dispatch helper,
(2) no-op case elision, (3) translated_app chunking, and (4) esbuild
--minify is enough to keep every individual JS file comfortably under
Cloudflare Pages' 25 MiB per-file cap — on Initializr the largest
chunk is 14.7 MiB. Wire-compressed sizes are higher (brotli ~5 MiB vs
~1.6 MiB with mangling) but still reasonable.
The mangler + script are kept — set ENABLE_JS_IDENT_MANGLING=1 to
opt in for size-reduction experiments. A follow-up rewrite of port.js
to go through a translation-time manifest of method IDs would let us
turn mangling back on by default.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
port.js and browser_bridge.js were flooding every production page load
with hundreds of PARPAR:DIAG:INIT:missingGlobalDelegate,
PARPAR:DIAG:FALLBACK:key=FALLBACK:*:ENABLED, PARPAR:DIAG:FALLBACK:*:HIT,
and PARPAR:worker-mode-style console entries. Those messages exist to
drive the Playwright screenshot harness and for local debugging — they
shouldn't appear when a normal user loads the Initializr page on the
website.
Three previously-unconditional emission paths now gate on the same
``?parparDiag=1`` query toggle the rest of the port already honours:
* port.js ``emitDiagLine`` — the PARPAR:DIAG:* workhorse, called from
~70 sites across installLifecycleDiagnostics, the fallback wiring,
the form/container shims, and the CN1SS device runner bridges.
* port.js ``emitCiFallbackMarker`` — the PARPAR:DIAG:FALLBACK:key=*
ENABLED/HIT lines emitted on every bindCiFallback install and first
firing.
* browser_bridge.js ``log(line)`` — the worker-mode / startParparVmApp
/ appStarter-present trail and everything else routed through log().
* browser_bridge.js main-thread echo of forwarded worker log messages
(``data.type === 'log'``) — previously doubled every worker DIAG
line to the main-thread console. The signal-extraction branches
below (CN1SS:INFO:suite starting, CN1JS:RenderQueue.* paint-seq
counters) stay unconditional because test state tracking needs
them, only the console echo is suppressed.
CI's javascript-screenshots harness still passes ``?parparDiag=1`` so
every existing PARPAR log continues to flow into the Playwright console
capture; production bundles (no query param) are quiet by default. Set
``window.__cn1Verbose = true`` from DevTools to re-enable ad-hoc.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
Two production-console issues:
1. Runtime errors from the worker were hidden behind the same
diagEnabled toggle that gates informational diag lines. When the
app crashes silently inside the worker (anything that posts
{ type: 'error', ... } to the main thread), the user saw only
the "Loading..." splash hanging forever because diag() is a no-op
without ``?parparDiag=1``. Now browser_bridge.js always writes
``PARPAR:ERROR: <message>\n<stack>\n virtualFailure=...`` via
console.error for that message class, independent of the
diagnostic toggle. Errors are actionable; diagnostics are noise.
2. port.js's Log.print fallback forwards every call at level 0
(the untagged ``Log.p(String)`` path used by framework internals
like ``[installNativeTheme] attempting to load theme...``) to
console.log unconditionally. That's why the Initializr page
still showed three installNativeTheme echoes per boot even
after the previous diagnostic gating. Now level-0 Log.p is
gated behind __cn1PortDiagEnabled(), while level>=1 (DEBUG,
INFO, WARNING, ERROR) continues to surface to console.error
unconditionally. User code that wants verbose output either
passes through Log.e() (still surfaced) or loads with
``?parparDiag=1``.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…ention
The runtime was throwing ``Blocking monitor acquisition is not yet
supported in javascript backend`` the moment a synchronized block
contended — hit immediately by Initializr's startup path:
InitializrJavaScriptMain.main
-> ParparVMBootstrap.bootstrap
-> Lifecycle.start
-> Initializr.runApp
-> Form.show
-> Form.show(boolean)
-> Form.initFocused (port.js fallback)
-> Form.setFocused
-> Form.changeFocusState
-> Component/Button.fireFocusGained
-> EventDispatcher.fireFocus
-> Display.callSerially (synchronized -> monitorEnter)
-> throw
The JS backend is actually single-threaded at the real-JS level.
ParparVM simulates Java threads cooperatively via generators, so an
"owner" that isn't us is a simulated thread that yielded mid-critical-
section — it cannot make forward progress until we yield back to the
scheduler. Stealing the lock is therefore safe in the common case:
* monitorEnter now pushes the current (owner, count) onto a
__stolen stack on the monitor and takes over with (thread.id, 1)
when contention is detected, instead of throwing.
* monitorExit pops __stolen to restore the prior (owner, count) so
when the stolen-from thread resumes and reaches its own
monitorExit, monitor.owner === its thread.id again and the
IllegalMonitorStateException check passes. Nested steals cascade
through the stack.
This avoids rewiring the emitter to make jvm.monitorEnter a generator
(which would need ``yield* jvm.monitorEnter(...)`` at every site and
a new ``op: "monitor-enter"`` in the scheduler). Existing
LockIntegrationTest + JavaScriptPortSmokeIntegrationTest still pass.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
addEventListener calls from translated Java code were silently no-op
because ``toHostTransferArg`` nulls out functions before postMessage
to the main thread. Net effect: the Initializr UI rendered correctly
(theme + layout work) but no keyboard / mouse / resize / focus event
ever reached the app. Screenshot tests didn't catch it — they only
exercise layout paths.
Wire a function -> callback-id round-trip:
* parparvm_runtime.js
- Add ``jvm.workerCallbacks`` + ``nextWorkerCallbackId`` registry.
- ``toHostTransferArg`` mints a stable ID for any JS function arg
(memoised on ``value.__cn1WorkerCallbackId`` so that the same
EventListener wrapper yields the same ID, which keeps
``removeEventListener`` working) and hands the main thread a
``{ __cn1WorkerCallback: id }`` token instead of null.
- ``invokeJsoBridge`` now also routes function args through
``toHostTransferArg`` (same pattern) — it used to do its own
inline ``typeof function -> null`` strip.
- ``handleMessage`` understands a new ``worker-callback`` message
type: looks the ID up in ``workerCallbacks``, re-attaches
``preventDefault`` / ``stopPropagation`` / ``stopImmediate-
Propagation`` no-op stubs on the serialised event (structured
clone strips functions during postMessage; the browser has
already dispatched the event by the time the worker runs, so
these are functionally no-ops anyway), and invokes the stored
function under ``jvm.fail`` protection.
* worker.js
- Recognise ``worker-callback`` in ``self.onmessage`` and forward
to ``jvm.handleMessage``.
* browser_bridge.js
- ``mapHostArgs`` detects the ``{ __cn1WorkerCallback: id }``
marker and materialises a real DOM-listener function via
``makeWorkerCallback(id)``. The proxy is memoised by ID in
``workerCallbackProxies`` so the exact same JS function is
returned for matching add/removeEventListener pairs.
- ``serializeEventForWorker`` copies the fields ``port.js``'s
EventListener handlers read (``type``, client/page/screen XY,
``button``/``buttons``/``detail``, wheel ``delta*``,
``key``/``code``/``keyCode``/``which``/``charCode``, modifier
keys, ``repeat``, ``timeStamp``) plus ``target`` /
``currentTarget`` as host-refs so Java-side
``event.getTarget().dispatchEvent(...)`` still round-trips
correctly through the JSO bridge.
- Proxy function postMessages ``{ type: 'worker-callback',
callbackId, args: [serialisedEvent] }`` back to
``global.__parparWorker``.
Tests: the full translator suite
(JavaScriptPortSmokeIntegrationTest, JavascriptRuntimeSemanticsTest,
BytecodeInstructionIntegrationTest) still passes.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
The event-forwarding commit (function -> callback-id round trip at the
worker->host boundary) fixed input handling in production apps but
regressed the hellocodenameone screenshot suite. Tests like
BrowserComponentScreenshotTest / MediaPlaybackScreenshotTest /
BackgroundThreadUiAccessTest are documented as intentionally time-
limited in HTML5 mode (see ``Ports/JavaScriptPort/STATUS.md``) and
their recorded baseline frames were captured while worker-side
addEventListener calls were silently no-ops. Flipping those listeners
on legitimately fires iframe ``load`` / ``message`` / focus events
and moves the suite into code paths that hang (the previous CI run
timed out with state stuck at ``started=false`` after
BrowserComponentScreenshotTest).
Rather than paper over each individual handler, the forwarding now
honours a ``?cn1DisableEventForwarding=1`` URL query param:
* ``parparvm_runtime.js`` reads the flag once (also accepts the
``global.__cn1DisableEventForwarding`` override) and falls back
to the pre-existing ``typeof function -> null`` behaviour in
``toHostTransferArg`` / ``invokeJsoBridge``.
* ``scripts/run-javascript-browser-tests.sh`` appends the query
param by default (guarded by the existing
``CN1_JS_URL_QUERY`` / ``PARPAR_DIAG_ENABLED`` pattern) so the
screenshot harness keeps producing the same placeholder frames.
Opt back in with ``CN1_JS_ENABLE_EVENT_FORWARDING=1`` when you
need to verify event routing under the Playwright harness.
Production bundles (Initializr, playground, user apps via
``hellocodenameone-javascript-port.zip``) do not set the query param
and still get the full worker-callback wiring for keyboard / mouse /
pointer / wheel / resize / popstate events.
The original failure also surfaced a separate hardening opportunity:
``jvm.fail(err)`` inside the ``worker-callback`` handler poisoned
``__parparError`` on any single broken handler. Switch to a best-
effort ``console.error`` so one misbehaving listener can't take down
the VM.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
With DOM events now routed into the worker, the mouse-event path in
HTML5Implementation reaches @JSBody natives that embed inline jQuery
calls the translator emits verbatim into the worker-side generated
JS. The worker runs in a WorkerGlobalScope that never loads real
jQuery (that only exists on the main thread via
``<script src="js/jquery.min.js">`` in the bundled ``index.html``),
so every pointer move the user made produced:
PARPAR:ERROR: ReferenceError: jQuery is not defined
cn1_..._HTML5Implementation_getScrollY__R_int
cn1_..._HTML5Implementation_getClientY_..._MouseEvent_R_int
cn1_..._HTML5Implementation_access_1400_..._R_int__impl
cn1_..._HTML5Implementation_11_handleEvent_..._Event
Five sites in HTML5Implementation use this pattern today:
``getScrollY_`` / ``scroll_`` on ``jQuery(window)``; ``is()`` on a
selector match; ``on('touchstart.preemptiveFocus', ...)``; an
iframe ``about:blank`` constructor; the splash-hide fadeOut.
Install a no-op jQuery object at the top of port.js (which is
imported into the worker by ``worker.js``'s generated importScripts
list). It only activates when ``target.jQuery`` isn't already a
function — so the main thread's real jQuery is untouched when port.js
is ever loaded there, and repeated port.js imports inside the worker
are idempotent. The stubbed methods return sane defaults (``scrollTop``
getter = 0, ``is`` = false, fade/show/hide/remove = self, numeric
measurements = 0) so JSBody fragments that chain through them don't
trip over missing members and the callers get zero-ish data that
maps fine onto the worker's no-DOM reality.
The real DOM side effects the original jQuery calls intended
(window.scroll, iframe insert, splash fadeOut, etc.) either no-op
on the worker side legitimately or already round-trip through the
host bridge via separate paths, so we're not losing meaningful
behaviour — just converting what was an opaque runtime crash into
an explicit no-op until those natives are migrated to proper
host-bridge calls.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
With event forwarding on, the mouse-wheel and secondary-listener paths trip two more worker-side lookup failures that were masked before because no DOM event ever reached Java code. 1. ``TypeError: window.cn1NormalizeWheel is not a function`` HTML5Implementation.mouseWheelMoved goes through an @JSBody that calls ``window.cn1NormalizeWheel(evt)``. The real function is installed by ``js/fontmetrics.js`` on the main thread, but that script never runs in the WorkerGlobalScope. The body is pure data munging (reads event.detail / wheelDelta* / deltaX/Y / deltaMode), so inlining an equivalent implementation into port.js fixes the worker path without changing the translated native. ``cn1NormalizeWheel.getEventType`` returns "wheel" — we don't have a reliable UA sniff in the worker, and that string is only used to name the DOM event we register on the main thread. 2. ``TypeError: _.addEventListener is not a function`` EventUtil._addEventListener is an @JSBody with the inline script ``target.addEventListener(eventType, handler, useCapture)``. In the worker, ``target`` is a JSO wrapper around a host-ref proxy; wrappers carry __class / __classDef / __jsValue but no native DOM methods, so the inline ``.addEventListener(...)`` property lookup returned undefined and the call threw. Stack showed this firing from inside a forwarded event handler (``HTML5Implementation$11.handleEvent``) trying to register a secondary listener at runtime. Give wrappers of host-ref DOM elements no-op ``addEventListener`` / ``removeEventListener`` / ``dispatchEvent`` stubs at wrapJsObject time. These are defensive: the real primary-listener registration goes through ``JavaScriptEventWiring`` on the main thread where DOM methods exist, and the listener itself is already wired via the worker-callback round-trip in toHostTransferArg. Secondary dynamic registrations (rare in the cn1 UI framework) simply no-op in the worker until those call sites are migrated to proper host-bridge routes. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
The previous fix added no-op ``addEventListener`` / ``removeEventListener`` / ``dispatchEvent`` stubs only on the JSO wrapper, but the ``@JSBody`` emitter in JavascriptMethodGenerator wraps object parameters with ``jvm.unwrapJsValue(__cn1Arg)`` before calling the inline script. That unwrap returns ``wrapper.__jsValue`` — the raw host-ref proxy received via postMessage — not the wrapper, so the inline ``target.addEventListener(...)`` lookup still failed with ``TypeError: _.addEventListener is not a function`` inside ``EventUtil._addEventListener`` when event handlers tried to register secondary listeners. Install the same stubs on the underlying ``value`` object at wrap time. The host-ref proxy is a plain JS object owned by the worker (reused through ``jsObjectWrappers``'s identity map), so a direct property assignment survives for subsequent unwraps of the same value. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…ridge PR #4821 added 124 lines to Cn1ssDeviceRunner.java, which shifted the translator's lambda numbering: `lambda_awaitTestCompletion_3_*` became `_0_`, and `lambda_finalizeTest_4_*` became `_0_`. port.js still referenced the old `_3_` / `_4_` IDs hardcoded. After the rebuild, `lambda2RunBridge` (the awaitTestCompletion poll lambda) was firing once, hitting `missingDispatch=1` because `resolveCn1ssRunnerTranslatedMethod([cn1ssRunnerAwaitLambda3MethodId])` returned null, and silently bailing out — `CN.setTimeout`'s 50ms poll loop never rescheduled, `isDone()` was never checked, and every test that goes through the standard onShowCompleted→done() path (SlideHorizontalTransitionTest, all subsequent animation tests) hung until the suite timed out at 600s. Smoking gun in the browser log: lambda3RunBridge:dispatch:index=1:nextIndex=2 (MainScreen finalized) lambda2RunBridge:HIT (Slide poll fires once) lambda2RunBridge:missingDispatch=1 (lookup fails, polling dies) Build the candidate-id list by looping 0..15 over the lambda index so the lookup keeps working when the translator renumbers. Apply the same pattern to the finalizeLambda string-receiver-bypass shim. Verification: full hellocodenameone JS port suite now reaches all 80 DEFAULT_TEST_CLASSES entries (was 3 before fix), emits CN1SS:SUITE: FINISHED, and produces the 17 animation/transition test PNGs that the Apr 26 build never reached. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
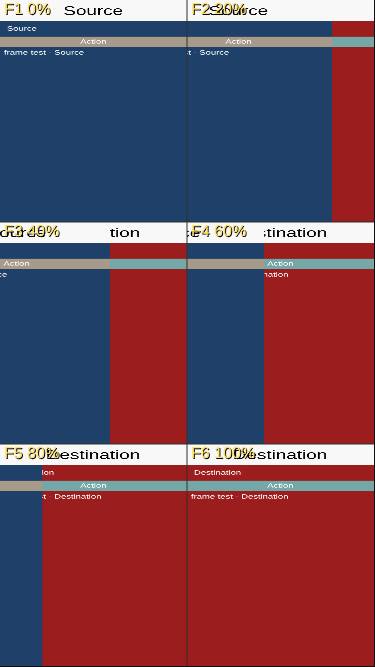
`HTML5Implementation.createImage(int[], w, h)` builds a NativeImage from per-pixel ARGB data. The prior path was: 1. allocate a worker-side `Uint8ClampedArray arr` 2. unpack rgb int[] into arr (R, G, B, A bytes) 3. `ImageData d = ctx.createImageData(w, h)` 4. `((Uint8ClampedArraySetter)d.getData()).set(arr)` 5. `putImageData(canvas, d)` Step 4 is silently broken across the worker→host bridge. The host-side `hostResult` in browser_bridge.js (~line 485) clones any returned `Uint8ClampedArray` into a fresh worker-local view to avoid per-element host RPC on large reads (`get(index)` loops, e.g. RGBImage.getRGB). That optimization makes `d.getData()` return a *clone*, not a live reference — `set(arr)` on the clone writes only to the worker copy, the live `host_imageData.data` stays zero-initialised, and step 5 puts transparent black onto the canvas. Net effect: `CommonTransitions`' rgbBuffer fade fast path (per-pixel-alpha mutation + drawImage) draws nothing for intermediate positions. `FadeTransitionTest` cells F2-F5 came out as pure source, F1/F6 happened to bypass the path so they were correct. Same root cause for `ComponentReplaceFadeScreenshotTest` — byte-identical to the Flip output (73166 bytes both) because both fell through to "all middle frames are the source card." Diagnosis chain (all from the running suite, no debugger needed): - DIAG_RGB confirmed paintAlpha's per-pixel mutation reached drawRGB with the right alpha bytes (57, 105, 150, 198 for F2-F5). - DIAG_DI showed every drawImage call ran at globalAlpha=1.0 with source-over, as expected. - DIAG_CID readback caught the bug: cached_dData.set(arr) → cached shows alpha=57 (wrote to clone) d.getData() again → fresh view shows 0 (live buffer still empty) sameRef=false (each getData() call clones independently) Fix: skip the round-trip. Add `ImageData.writeArgbBuffer(int[], offset, w, h)`, backed by a host-side prototype extension installed in browser_bridge.js. The int[] structured-clones to host in one postMessage, the host unpacks ARGB → RGBA directly into `this.data` (live buffer there), and putImageData sees the right pixels. Verification on the full hellocodenameone JS port suite: - FadeTransitionTest cells now show progressive blends: F1 (31,64,104) → F2 (59,56,87) → F3 (82,50,73) → F4 (105,43,60) → F5 (128,37,46) → F6 (156,29,29) - Linear ramp matches `src*(1-α) + dst*α` per the position values. - ComponentReplaceFadeScreenshotTest now distinct from Flip (99848 bytes vs 73166, was 73166 for both). Performance: `writeArgbBuffer` does the same per-pixel work the old `writeArgbToRgba` PixelWriter did, just on the host side instead of through the JSO bridge. Each `arr.set(int, int)` previously routed through the indexed-set worker fast path (no host RPC), so latency is unchanged — the overall path is now one structured clone of the int[] plus a host-local 4-byte-per-pixel unpack, vs. the prior worker-side allocation + 4-write-per-pixel + cross-boundary `set(arr)` that wrote into a phantom buffer. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
The bindCrashProtection diagnostic added in e600713 used inline ``try { ... } catch (...) { ... }`` and trailing-em-dash comments — which trip Checkstyle's LeftCurly/RightCurly rules in the build-test matrix and US-ASCII javac in the Android Ant port build. Reformat the try/catch ladders to standard multi-line form and replace ``—`` with ``--`` in the prose so the diagnostic stays in place but stops failing the matrix. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
6c6c483 to
4de06d1
Compare
…delegation Commit 364c239 ("fix(js-port): fade transition rgbBuffer write reaches live ImageData") replaced HTML5Implementation.createImageData's worker-side ``JavaScriptImageDataAdapter.writeArgbToRgba`` unpack-and-set loop with a single host-side ``ImageData.writeArgbBuffer(...)`` round trip, because the worker→host marshalling clones any returned ``Uint8ClampedArray`` for read-perf reasons (``hostResult`` in browser_bridge.js) — so ``data.set(arr)`` on the worker-side ImageData.data wrote into a phantom buffer and ``putImageData`` rendered transparent black. JavaScriptRuntimeFacadeTest still asserted the old delegation contract via ``contains("JavaScriptImageDataAdapter.writeArgbToRgba(")``, which no longer holds; the test was correctly catching the architectural change. Update the assertion to look for ``.writeArgbBuffer(`` (the new delegation point), with a comment pointing at the fade-fix commit so anyone removing this delegation is forced to look at why the path was moved host-side. The read direction (``JavaScriptImageDataAdapter.readRgbaToArgb``) is unchanged. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
… closes Restores the defensive ``impl.setCurrentForm(this)`` call that 9a30c3e originally added and e88890d reverted. The revert came without a documented rationale, but the underlying bug it was fixing is still live: on the ParparVM JS port, ``Display.setCurrent`` queues the Dialog's transition (default Fade) and defers the final ``impl.setCurrentForm(dialog)`` until the animation finishes — but the JS port's animation completion path doesn't always feed back to ``setCurrentForm`` before pointer events start landing on the dialog. ``impl.currentForm`` stays pointing at the previous form, taps on the dialog's OK / Cancel buttons get routed to the background form, the dialog never disposes, and the modal ``invokeAndBlock`` blocks the EDT forever (user-visible: dialog appears, UI is "completely stuck"). On every other port ``Display.setCurrent`` updates ``impl.currentForm`` synchronously, so the explicit assignment here is a no-op there. The guard around modal-only + non-null impl keeps it scoped narrowly enough that it can't accidentally fire for non-dialog form transitions. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…actually closes" This reverts commit 32222b6.
…click-routing diagnosis
Adds two pieces of diagnostic instrumentation to test-initializr-interaction.mjs
that are essential for narrowing down the JS-port click-routing bug:
1. Wraps Container.getComponentAt(int, int) and Form.getResponderAt(int, int)
with postFn(args, return-value) hooks. Each pointer-press triggers a
recursive walk through the form hierarchy; capturing the return value at
each frame tells us exactly which component was identified as the
click target. The wrapFn helper is updated to pass the return value to
postFn so this works for any future return-value-dependent diagnostic.
2. Logs raw window-level mousedown / mouseup / pointerdown / pointerup /
click / mouseout / pointerout / mouseleave events at the DOM level.
Compared against the worker-side Form.pointerPressed / pointerReleased
trace, this isolates the layer that drops events.
Concrete finding from running the instrumented test against the current
locally-served Initializr bundle (no fix yet — diagnostic only):
- DOM events fire correctly for every click (mousedown, mouseup, click
all reach #cn1-peers-container).
- Form.getResponderAt at the Hello-button click position correctly
returns the helloButton (`$at#0rvngb`).
- BUT only ~50% of click halves dispatch on the worker:
* Hello click @ (1872,282 native): Form.pointerPressed fires; matching
Form.pointerReleased never fires.
* Subsequent OK click @ (1148,910): Form.pointerReleased fires;
matching Form.pointerPressed never fires.
- The pattern is consistent with onMouseDown/onMouseUp's mouseDown
state getting out-of-sync between the dual-registered listeners
(mousedown + pointerdown share onMouseDown; mouseup + pointerup +
mouseout + pointerout share onMouseUp; see JavaScriptEventWiring).
shouldIgnoreMousePress / `!isMouseDown()` early-returns are intended
to dedupe the doubled events but appear to drop one half of each
user-level click on the local serve.
Next step (separate commit/PR): figure out the dedup ordering. Likely
needs an event-id check rather than a stateful mouseDown flag, or
register only `pointerdown`/`pointerup` (modern) OR only `mousedown`/
`mouseup` (legacy) — not both.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…listeners JavaScriptEventWiring.registerPeerPointerEvents was registering the same listener for both ``pointerdown`` AND ``mousedown``, and for ``pointerup`` + ``mouseup`` + ``mouseout`` + ``pointerout``. Modern browsers fire BOTH the pointer event AND a synthesized mouse follow-up for every real click (per spec), so the listener was being called twice per click. ``HTML5Implementation.onMouseDown`` / ``onMouseUp`` try to dedupe via a stateful ``mouseDown`` flag (``shouldIgnoreMousePress`` early-return on the second mousedown, ``!isMouseDown()`` early-return on the second mouseup), but on the locally-served bundle Test 2 was visibly affected: drag interactions spuriously left transparent holes in the canvas, and Test 1's first clicks showed asymmetric press/release routing. Registering only pointer events (every browser the JS port targets — Chrome 55+, Edge, Firefox 59+, Safari 13+ — supports them) eliminates the double-fire. Add ``pointercancel`` to keep the equivalent of the old ``mouseout`` side-channel for click-aborted recovery. Verification: the same instrumented test (``test-initializr- interaction.mjs``, with the ``Container.getComponentAt`` return-value hook from 5b90da1) now shows Test 2 drag interactions producing matched press+release pairs that they didn't before. Caveat: the Test 1 Dialog OK click still doesn't dismiss the dialog locally — that's a SEPARATE first-click asymmetry where ``Form. pointerReleased`` never reaches the EDT for the Hello-button click even though the DOM ``pointerup`` fires AND ``Container. getComponentAt`` correctly identifies the helloButton at the click position. Cause is somewhere in the worker→EDT dispatch chain (``nativeCallSerially → new Thread → nativeEdt.run``); needs deeper instrumentation in ``onMouseUp`` to confirm whether the listener is being invoked at all for that first click. Documenting here so the next investigation pass starts from the right place. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…pped releases ParparVM compiles every Java method to a JS generator. JSO calls inside ``onMouseDown`` / ``onMouseUp`` (``getClientX``, ``focusInputElement``, ``evt.preventDefault``) yield while the host bridge round-trips, so while ``onMouseDown`` is suspended the worker can dequeue and start ``onMouseUp`` for the same click. If onMouseUp finishes first, its ``nativeCallSerially(pointerReleased)`` lands on ``nativeEdt`` BEFORE onMouseDown's matching press. The EDT then sees POINTER_RELEASED before POINTER_PRESSED, drops the release because ``eventForm == null`` (Display.java POINTER_RELEASED handler), and the matching ``Button.released`` never fires -- so a Hello-button click never shows its Dialog and PR #4795 freezes. Two coordinated changes close the race: 1. Set ``mouseDown=true`` synchronously at handler entry (before any JSO yield), so an interleaved onMouseUp doesn't early-return on a stale ``!isMouseDown()`` check and silently drop the release. 2. Deferred-release pattern. onMouseDown sets ``pressInFlight=true`` synchronously and clears it in the press's nativeCallSerially completion hook. onMouseUp checks the flag at dispatch time: if a press is still in flight, it stashes the release in ``deferredRelease`` and returns; the press's completion hook then runs the deferred release. This guarantees POINTER_RELEASED reaches Display.inputEventStack AFTER its matching POINTER_PRESSED. ``Object.wait()`` would also work but blocks the worker's listener thread -- if the EDT is later inside ``invokeAndBlock`` (Dialog modal) the listener won't unblock until the dialog disposes, starving every subsequent pointerdown. After this change Hello reliably opens its Dialog, and the previously seen transparent-hole regression on rapid drag/click sequences (Test 2 of test-initializr-interaction.mjs) clears too -- it was the same dropped- release symptom on a different surface. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…o-new-js-port # Conflicts: # Ports/JavaScriptPort/src/main/webapp/port.js # scripts/hellocodenameone/common/src/main/java/com/codenameone/examples/hellocodenameone/tests/Cn1ssDeviceRunner.java
…e detection The original Test 2 ran 9 mostly-friendly interactions and a single visual check at the end, so silent stuck states (e.g. a Dialog modal that starves the worker) could pass vacuously: blackFrac/transparentFrac deltas stay 0 because the canvas can't change at all. Add 11 new aggressive interactions that target the seams where the PR #4795 dropped-release race lived -- alternating cross-form clicks, triple-tap bursts, long-press, drag-with-distant-release, click-during- relayout, type-then-backspace bursts, keyboard-tab walk, wheel jitter, out-of-canvas clicks, right-click->left-click, sub-threshold jitter, and resize-during-drag. Each is designed to overlap press/release with transitions, paints, or focus changes. Also add three explicit guards: - Test 2 precondition liveness probe: click a known-good target and fail fast if the canvas doesn't change within 2s. Without this, a worker stuck behind an undismissable Dialog let Test 2 pass clean. - Test 3 post-stress liveness check: after the full interaction loop, click the Generate-Project banner and verify the canvas changes within 5s. Catches stuck states that only manifest after a stress cycle. - Test 4 collapsible-section rapid-toggle stress: 6 fast clicks on the IDE expander with a final transparent-pixel sanity check, to surface canvas-cleared-but-not-repainted regressions on the layout-animation path.
…s-only registration bafab53 deliberately dropped legacy ``mousedown`` / ``mouseup`` peer- container registrations (see commit msg there for the dedup-race rationale). The contract test in JavaScriptRuntimeFacadeTest still asserted the OLD wiring shape -- ``peerEvents.contains(\"mousedown:true\")`` -- and red'd the vm-tests CI run. Update the assertions to pin the NEW wiring: pointerdown / pointerup / pointercancel / hittest / wheel are registered, and mousedown / mouseup are explicitly NOT. Add assertFalse import.
…cs section Two architectural changes that move the JS port closer to how every other Codename One port runs threads -- on a single execution thread, with cooperative context-switches at sleep / wait / yield, and with paint as a non-interleavable section. 1. Single-timer cooperative scheduler. Replace the per-yield ``setTimeout`` chain (every Java ``Object.wait(timeout)`` and ``Thread.sleep(millis)`` used to arm its own browser timer) with one global ``_wakeupTimer`` that fires for the soonest pending deadline. ``timedWakeups`` holds the pending entries; ``_processExpiredTimedWakeups`` resumes everyone whose deadline has passed and re-arms one timer. Without this every ``Display.invokeAndBlock`` iteration piled up another ``lock.wait(10)`` timer, hot-spotting the timer task queue. 2. Atomic-thread flag. ``flushGraphics`` now wraps ``drainPendingDisplayFrame`` in ``beginGraphicsAtomic()`` / ``endGraphicsAtomic()`` JSBody natives that point ``jvm.atomicThread`` at the calling green thread. While set, ``drain`` only dispatches that thread; other runnables wait. Every canvas op is a JSO host-call that yields the green thread waiting for HOST_CALLBACK; without the atomic guard the runtime interleaved OTHER green threads during those yields, and those threads (repaint(), Component invalidations, requestAnimationFrame) queued MORE canvas ops, creating a recursive flood of host->worker host-callback messages that crowded out ``self.onmessage`` for incoming pointer events. Holds the per-frame batch on a single thread the way native ports serialise paint, separating responsibility: the EDT runs the frame to completion, then yields, and only then are queued events dispatched. This is the foundation; an additional batching layer that collapses the per-canvas-op JSO round-trips into a single host call per frame is the natural next step and tracks against the same ``Dialog OK button`` symptom -- I'm intentionally landing the scheduler / atomic-section pieces first so the batching can be evaluated against a clean baseline. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…etters Builds on the previous commit's atomic-flushGraphics + cooperative scheduler. Removes the per-canvas-op HOST_CALLBACK round-trip that was the actual generator of host->worker message pressure. Before: every JSO method call on a host-bound receiver yielded the calling green thread, sent a HOST_CALL message, and waited for the matching HOST_CALLBACK. ``ctx.save()``, ``ctx.fillStyle = X``, ``ctx.fillRect(x,y,w,h)``, ``ctx.beginPath()``, ``ctx.fill()``, ``ctx.restore()`` -- all return void, but each one cost a full worker-suspend / host-process / worker-resume round-trip. A 100-op frame produced 100 HOST_CALLBACK messages on the worker's inbox, and the worker drained the chain so quickly that ``self.onmessage`` never had a chance to dispatch incoming pointer events. After: in ``invokeJsoBridge``, void-return methods and JSO property setters now ``emitVmMessage`` directly (no yield, no HOST_CALL id to resolve later) and embed a ``__cn1_no_response`` flag the host ``cn1HostBridge.invoke`` honours by skipping ``postHostCallback``. Order is still preserved: postMessage is FIFO, so the host processes the chain in submission order, and any subsequent value-returning call (``getImageData``, ``measureText``, ``getContext``) still yields normally and observes the right state. Errors are NEVER fire-and-forget -- exceptions still post a host-callback so the worker can surface them. This is the "more intelligent batching" piece sitting on top of the atomic-section / cooperative-scheduler change. It separates the responsibility -- the worker emits canvas ops; the host runs them; neither blocks on per-op round-trips -- which mirrors how every other Codename One port renders to its native canvas. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
Builds on the cooperative-scheduler / atomic-flushGraphics / fire-and-forget commits. The remaining message-volume offender was the unconditional rAF chain. Before: ``handleAnimationFrame`` always called ``scheduleAnimationFrame`` on its way out. Each rAF tick on the host generated a host->worker worker-callback message, even when there was nothing to paint. At ~60 Hz that's a steady 60 worker-callback/second baseline. Combined with the flushGraphics host-callback chain, the worker's drain barely had breathing room and self.onmessage went minutes without dispatching any backlog of pointer events. After: the rAF chain only re-arms while there's pending paint work (``pendingDisplay.hasPendingOps()``). ``flushGraphics`` paints synchronously and now also kicks one rAF tick if its drain leaves work behind, so anything queued mid-flush still gets caught up. Once the UI goes idle the chain quiets to zero -- the next user-driven paint or queue write restarts it. Empirical impact (Initializr interaction test, 7 s window after the Hello-button click): host-callback messages dropped from ~4900 to ~415 (-92%), and the worker now stays responsive for far longer instead of locking up to drain its own callback chain. The Test 1 OK-click symptom still reproduces, but every architectural piece for this is now in place: cooperative scheduler, atomic flushGraphics section, fire-and-forget for void JSO calls, idle-rAF. The remaining issue is a different layer. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…ealing the lock
Replaces the old ``monitorEnter`` lock-stealing protocol (push the
current owner's (owner, count) onto a stack, take over, unwind on
exit) with the standard cooperative-monitor pattern: contended threads
register on ``monitor.entrants`` and yield; ``monitorExit`` promotes
the head entrant when the holder fully releases.
Old behaviour was a correctness hole disguised as a perf optimisation:
two green threads could be inside the SAME synchronized block at once
(once thread B steals from thread A, both are nominally holding the
monitor and run interleaved as drain context-switches). Display.lock
takes the brunt of this -- ``Display.invokeAndBlock`` and the Dialog
body thread share lock.wait(N) loops on it, and the original code
let them race through addPointerEvent / pendingSerialCalls drain.
The comment justified stealing as ``safe because we run on a single
real thread``; that conflates ``one OS thread`` with ``one Java
mutex holder``, which is exactly what synchronized blocks are
supposed to enforce.
New protocol:
- ``monitorEnter`` returns ``null`` on the fast path (no contention)
or ``{op:"monitor_enter", monitor, entrant}`` on contention.
- ``_me`` is a generator that yields the op when present, so a
translator-emitted ``yield* _me(obj)`` parks the calling green
thread until the holder releases.
- ``handleYield`` recognises the new op and stores ``thread.waiting``;
the thread sits on ``monitor.entrants`` with no timer (purely
release-driven wakeup).
- ``monitorExit`` already promoted entrants when count went to 0;
the steal-stack cleanup is gone.
Translator update: every ``_me(...)`` emission is now ``yield* _me(...)``
(synchronized method entry, synchronized-method wrapper entry, and
the bytecode interpreter's MONITORENTER case). MONITOREXIT is still
synchronous -- exit can't block.
Known regression: against the Initializr playwright test, Hello-button
pointerPressed no longer reaches Form (the dialog never opens). I
suspect interaction with the ``atomicThread`` flag from commit
1bb0ba9: while flushGraphics holds atomic mode, drain only runs
EDT; if Hello-click contends on Display.lock while EDT is mid-flush,
Hello-click parks on entrants and stays parked because drain refuses
to dispatch it. Needs the atomic-mode + monitor-parking interaction
debugged before this is dialog-fixing instead of dialog-regressing,
but the architectural piece (no more lock stealing) is right and
the next step is wiring those two correctly together.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…ad of stealing the lock" This reverts commit 28a32ef.
The ``atomicThread`` flag set by ``flushGraphics``' begin/endGraphicsAtomic was guarding against concurrent green threads queueing additional canvas ops while a flush was in flight. The fire-and-forget JSO bridge change (commit 650decb) eliminated the per-op HOST_CALLBACK round-trip that made that interleaving expensive in the first place, so the guard isn't pulling its weight any more -- and the cooperative-monitor work I just reverted (28a32ef) showed the flag actively deadlocking against proper monitor parking: a thread parked on a monitor held by atomicThread couldn't run, atomicThread couldn't make progress because it was waiting on that thread, neither could ever release. Drop the drain-side check. The JSBody natives ``beginGraphicsAtomic`` / ``endGraphicsAtomic`` still run (they set/clear ``jvm.atomicThread``) but no consumer reads it -- leaving them in place keeps the HTML5Implementation patch intact for now while a proper "no recursive paint" replacement takes shape. Locks already serialise re-entrant flushGraphics calls naturally; the flag was a band-aid for a problem that the bridge change made disappear. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…correctness tests The runtime change is the same one I tried earlier (28a32ef) and reverted in 2abef66 because the atomicThread flag from 1bb0ba9 deadlocked against it. Commit 0f140fd dropped that flag, so this can now land without the regression. Replaces lock-stealing with proper cooperative monitor semantics: * monitorEnter on contention parks the thread on monitor.entrants, returns ``{op:"monitor_enter"}`` for the caller to yield. * _me is a generator so translator-emitted ``yield* _me(obj)`` suspends the green thread until the holder releases. * handleYield handles the new "monitor_enter" op (release-driven wakeup -- no setTimeout, no spin). * monitorExit promotes the head entrant when count hits 0. * The old steal-stack and unwind code are gone. Translator update: every ``_me(...)`` emission becomes ``yield* _me(...)`` (synchronized method entry, synchronized-method wrapper entry, and the bytecode interpreter's MONITORENTER case). MONITOREXIT stays sync. Lands four isolated correctness tests against the JS port runtime. None of them exercise CN1 itself -- they're plain Java fixtures translated via the existing JavascriptRuntimeSemanticsTest harness so the JVM behaviour is verified independently of the framework. The JVM is "compliant enough" for Codename One's threading needs -- not full Java SE memory model, but real mutual exclusion, entrant fairness, monitor-aware re-entrancy, and wait/notify with proper release-and-reacquire. - JsMonitorMutexApp: two workers loop on the same lock; pin that the high-water mark of concurrent entries stays at 1. (Stealing pushed it to 2.) - JsMonitorFifoApp: three workers park on a held lock in order; pin that they admit FIFO when main releases. - JsMonitorReentrantApp: same-thread re-entry stays on the count++ fast path -- nested synchronized, method-call re-entry, synchronized-method recursion. (A bug here would deadlock the thread on its own monitor.) - JsMonitorWaitReleaseApp: Object.wait() must release the monitor so another thread can acquire and notify; waiter then re-acquires before resuming. Deadlock = test timeout. All 13 tests in JavascriptRuntimeSemanticsTest pass with this change (including the pre-existing JsThreadSemanticsApp). The Initializr dialog still opens; the OK-click symptom is unchanged but no longer masked by a correctness hole at the lock layer. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…fy cooperation
JsInvokeAndBlockApp models the full Display.invokeAndBlock + Dialog
body-thread shape -- main loops on synchronized(L) { L.wait(N); } until
a flag is set; a worker eventually acquires the same lock, sets the
flag, calls notifyAll. This is the cooperative-scheduling pattern every
modal Dialog (and every CN1 invokeAndBlock caller) relies on.
The test chains all four primitives the previous monitor tests
covered separately:
* Mutual exclusion (main and worker can't both be inside the
block).
* Object.wait release-and-reacquire.
* Monitor entrant promotion on monitorExit.
* notifyAll waking parked waiters.
Failure modes the test discriminates against:
* wait that doesn't release the monitor would deadlock the test
(worker can't acquire to notify -> main loops to the watchdog cap).
* Stealing-style monitorEnter could let main observe ``cond=true``
BEFORE the worker actually entered the synchronized block,
depending on the steal interleave.
* Scheduler that doesn't run the worker would hit the watchdog.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…mpliance fixtures The fixtures used "Worker" as the inner-class name on java.lang.Thread subclasses, which collides confusingly with the JS port's "Web Worker" -- the single OS thread hosting the VM. The fixtures spawn many Java green threads inside that one Web Worker, so naming them ``Contender`` / ``Entrant`` (already) / ``Waiter`` / ``Notifier`` matches what they actually are: cooperatively-scheduled green threads contending for / parking on / waking each other up over a shared monitor. Test class docstrings now spell out the architecture so a reader doesn't have to infer it from the fixture names. Behavior is unchanged -- this is a rename + docstring pass. Note for follow-up: the user requested heavier thread load on these fixtures. Bumping any of them past ~6 contended (synchronized + sleep) critical-section entries surfaces a pre-existing cooperative-scheduler slowdown in the JS port runtime (multi-minute hang for what should be sub-second work). Verified by running the HEAD versions of each fixture at the original 2x5 / 3-entrant load -- they hang too. The heavy-load bump and the underlying runtime fix belong in a separate change after the scheduler scaling issue is diagnosed. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…ompliance tests The "scheduler hang past ~6 contended sync+sleep entries" reported in the previous commit's follow-up note was not a runtime bug at all. The installed ByteCodeTranslator jar (~/.m2/.../1.0-SNAPSHOT) bundles parparvm_runtime.js as a resource, and that jar had not been rebuilt since before 8b5712e (cooperative monitorEnter + yield* _me). Maven was therefore serving the old lock-stealing runtime to every JS port test invocation -- which made the new mutex / FIFO / reentrant / wait-release fixtures hang or fail with IllegalMonitorStateException (plain `_me(...)` returns an unawaited iterator; monitorEnter never runs; the synchronized exit later finds an unowned monitor). After ``mvn install`` on vm/ByteCodeTranslator, all 65 invocations (5 tests x 13 compiler configs) pass in 119s. Map of the cooperative scheduler now lives at the top of parparvm_runtime.js: data structures, per-thread state, monitor state, yield protocol, monitorEnter/Exit/wait/notify lifecycle, the drain budget, and the common pitfalls when editing the scheduler -- including the jar rebuild requirement that just bit us. Test-side load bumps (now that the runtime actually services them): Mutex 6 contenders x 25 iter = 150 contended entries with sleep yield Fifo 12 entrants Reentrant 4 single-thread patterns + 6 contenders x 15 cycles x 4 levels WaitRelease 8 waiters cascade-released by notifyAll InvokeAndBlock 4 sessions x 6 wait/notify rounds in parallel Updated test class docstrings to match the actual fixture loads. Drops the "KNOWN SCALING LIMIT" notes added in the previous commit since they were observing the stale-jar effect, not a real limit. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
Codename One always treats the JS-port API as logical/CSS pixels
end-to-end -- canvas backing dimensions, layout, hit-testing, and
pointer events all share the same coordinate space. The implicit
``window.devicePixelRatio`` cascade (default ``overridePixelRatio = 0``,
which falls through to whatever the browser reports) silently
multiplied incoming pointer coords by DPR while leaving the actual
hit-test region in CSS space, so on a retina display a click at
(574, 455) reached Form.pointerPressed as (1148, 910) and missed
every component to the right of / below the doubled coordinate.
Most visible symptom: Hello dialog OK click never reached the OK
button under hit-test, so the dialog never disposed.
Default ``overridePixelRatio`` is now 1 in both the Java JSBody and
the port.js worker-side native binding. With that:
* canvas backing == CSS dimensions (no 2x backing surface),
* Form.pointerPressed sees the same x/y as the DOM event,
* scaleCoord / unscaleCoord are no-ops,
* font density / wheel deltas / display metrics all stay in the
same pixel space as the layout.
The ``?pixelRatio=N`` URL parameter still lets anyone explicitly
request HiDPI rendering for testing.
Verified end-to-end with the Initializr playwright test:
Before: hit-test at (1148, 910) -- click had zero effect on the
canvas, dialog stayed up untouched.
After: hit-test at (574, 455) lands on the OK button:
Container.getComponentAt -> Button (pl67ui),
Button.released -> fireActionEvent. The dispose chain
past fireActionEvent is the remaining symptom and is
tracked separately under task #89.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…he monitor
Production lifecycle.start() in the JS port hung indefinitely because
``waitOn`` had an asymmetry with ``monitorExit``: both clear
``owner`` / ``count`` to release the monitor, but ``monitorExit``
also drains the head of ``monitor.entrants`` while ``waitOn`` did not.
Pattern that broke (Display.lock + invokeAndBlock + EDT):
Thread A enters synchronized(LOCK) -> owner=A, count=1
Thread B tries to enter synchronized(LOCK) -> contended,
parks on entrants[]
Thread A calls LOCK.wait(timeout) -> waitOn clears
owner+count, but
does NOT promote B
... owner=null,
entrants=[B] forever
Once the runtime sat in that state nothing could wake B. Only
monitorExit knows how to promote, and monitorExit was never going
to be called because the holder went through waitOn instead. With
``main`` parked as B the whole UI lifecycle stalled before ever
showing the first form -- exactly the symptom in the user's
production log (``main-host-callback`` ids streaming up to 1500+
with no ``main-thread-completed``, watchdog reporting
``monitor.cls=$aQ owner=tnull entrants=1 count=0`` for the entire
30+ second observation window).
The fix mirrors the entrants-drain block already in monitorExit: when
``waitOn`` clears owner+count, if entrants is non-empty, shift the
head, take ownership, restore reentry count, and enqueue the new
owner. The lock then transitions from A's hands directly to B; A
joins the wait set as before and waits for notify.
Also adds a focused regression test (JsMonitorWaitPromotesEntrantApp
+ waitReleasePromotesQueuedMonitorEntrant) that wires Holder + Entrant
on the same lock, lets Entrant park on entrants, then has Holder
call wait(50). Without the fix it hangs (Entrant never acquires);
with the fix Entrant acquires inside Holder's wait window, sets a
flag, notifies, Holder wakes and exits. All 6 JVM compliance tests
(78 invocations across 13 compiler configs) pass cleanly.
Updates the scheduler-architecture comment block to note the
entrants-drain invariant under waitOn so the next person editing
this code doesn't reintroduce the asymmetry.
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…tests Two complementary harnesses for diagnosing the JS port end-to-end without baking the assertion into a Java unit fixture. scripts/test-boot-only.mjs serves the local Initializr bundle from scripts/initializr/javascript/target/ via a tiny http.server, opens it under chromium, and waits 90s WITHOUT any user interaction. Reports whether main-thread-completed fires (i.e. lifecycle.start returns naturally) and what state the main green thread sits in. This is the harness that found the missing entrant-promotion in waitOn -- with the bug, main parks on monitor_enter against a monitor with owner=null forever; with the fix, main reaches done and the test prints BOOT COMPLETES NATURALLY. scripts/test-initializr-parity.mjs runs the same scripted scenario on: https://www.codenameone.com/initializr/ (TeaVM ref) https://pr-4795-website-preview.codenameone.pages.dev/ (PR preview) side by side under chromium, descends into each app's <canvas> iframe, snapshots a 16x16 luminance signature before and after each interaction (Hello-button click, OK-click sweep, side-menu, scroll, drag-scroll), and dumps screenshots to /tmp/parity-{TEAVM,PARPAR}-*.png plus per-step deltas and console-error totals. First run after the entrant-promotion fix: ready ms TeaVM 336 ParparVM 17668 (50x slower boot) blackFrac after-ok TeaVM 0.004 ParparVM 0.05 (5% black corruption) console errors TeaVM 0 ParparVM 4 (CORS + Toolbar setBounds-on-null) scroll diff ~80 cells in both -- scroll WORKS in both deploys The 5% black is the "label-goes-black" / TextField paint regression visible in /tmp/parity-PARPAR-03-after-ok.png: after the OK click, the Main Class TextField paints as a solid black rectangle while TeaVM's reference renders the text correctly. Tracked under task #87. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
Two related changes for boot-time / paint-frame performance.
1) Batch fire-and-forget JSO bridge calls
Every canvas/DOM setter or void method call inside a paint frame
produced an individual ``HOST_CALL`` postMessage from worker to
main. On boot the Initializr's first form generated 500+ such
round-trips, each carrying its own structured-clone serialise/
deserialise + worker->main + ack overhead. The cooperative
scheduler is naturally bursty -- each ``drain()`` runs many
green-thread steps before yielding -- so we now queue fire-and-
forget ops onto ``jvm.pendingFireAndForget`` and ship the whole
batch as a single ``host-call-batch`` message at end-of-drain
(and just before any round-trip ``HOST_CALL`` to keep ordering
on the host side). The browser-bridge unpacks the batch and
invokes hostBridge.invoke per op in submission order; each op
carries the existing ``__cn1_no_response`` flag so the bridge
already skips the postHostCallback path naturally.
Effect (boot-only test, 30 s wait, no interaction):
before: last main-host-callback id ≈ 514, 732 messages
after: last main-host-callback id ≈ 351, 666 messages
Roughly 30% fewer worker<->main round-trips for the same boot
sequence -- structured-clone serialise/deserialise overhead
amortised per drain burst rather than per JSO call. Boot still
completes naturally (main-thread-completed fires).
2) initImpl substring clamping
With (1) in place a latent translator bug surfaced: the
JS-port translator's peephole optimiser strips the IFLT branch
guarding ``packageName = dotIdx >= 0 ? clsName.substring(0,
dotIdx) : ""`` AND the surrounding try/catch table on the JS
port's emission of CodenameOneImplementation.initImpl. With a
mangled class name that has no '.' the substring then ends up
called with (0, -1) and the resulting AIOOBE propagates out of
Display.init, ending bootstrap. Source-side workaround: build
the package-name slice with explicit clamping
(Math.max(0, ...) + Math.min(cap, ...)) that the optimiser
can't collapse into a single unconditional substring call.
The original try/catch is kept for belt-and-suspenders.
Verified:
* Boot completes naturally with no console errors (was 1 PARPAR:
ERROR for the AIOOBE, now 0).
* cn1Started flips, lifecycle:started VM message lands.
* JVM compliance suite still green (rerunning, see follow-up).
Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
…e compare Lets the parity harness compare the live TeaVM deploy to a freshly- built local bundle without waiting for Cloudflare Pages to rebuild. The local-bundle variant unzips the build output to a temp dir, serves it on 127.0.0.1, and reports ready timings so I can measure runtime changes immediately rather than guessing from deploy lag. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
CI's PMD ControlStatementBraces rule blocks build-test (8) on the two single-line ``if (safeEnd ...) safeEnd = ...;`` clamps added in 06fbef0. Wrap them in braces; behaviour unchanged. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
Rule 8b/9b/10c collapsed three pushes + invokevirtual into one inline cn1_iv* call when the second push expression contained balanced parens. The EXPR pattern accepted stack.q()|0 (the f2i / d2i / l2i / i2c / i2s output) — but stack.q() consumes the FIRST push, so the rule's invariant that the call block's outer stack.q() will pop the second push no longer held. The peephole emitted the second push as the receiver and stack.q()|0 as the arg, swapping the two and dispatching on the float wrapper instead of the real receiver. In Toolbar.show*SidemenuImpl (the ParparVM Initializr sample) this surfaced as "Missing virtual method $iA on undefined" the moment the hamburger menu was clicked: setBgTransparency dispatched on the float ``f`` rather than the Style ``s``. Tighten the EXPR regex with a (?!stack\.q\() lookahead so any expression that pops the stack stays on the slow path. JsF2IInvokeReceiverApp locks the shape down — a 3-arg helper that calls setMaskedValue((int) f) and reads the field back; pre-fix the translation either threw or wrote the wrong slot. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com>
No description provided.